Call via Attributes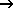 Compute Groundwater recharge… RUBINFLUX Generate input_id Interpolation weights ...
Compute Groundwater recharge… RUBINFLUX Generate input_id Interpolation weights ...
Theory
When using station data or coarser climate data (e.g., 1×1 km² resolution) , the resulting groundwater recharge rates often display sharp boundaries due to the higher spatial resolution of the groundwater model, where element edges are often less than 100x100 meters. This discrepancy between the input data resolution and the model resolution can lead to unrealistic sharp transitions in the results.
To mitigate these effects, an investigation was carried out to determine the feasibility of interpolating the climate parameters onto the support points of the model network. Testing various interpolation methods indicated that the inverse distance weighting (IDW) method, based on the nine nearest neighbour points and the inverse of the square distance to the target point , is the most suitable method. This method is verified technically and is widely used in meteorology, including by the German Weather Service for the interpolation of precipitation data from station measurements. Therefore, the three weighting methods are offered in the dialogue:
In the Assign attributes By interpolation menu, users can read in files in *.txt or similar formats, or structure data formats.. The files contain the information x, y and input_id number of the stations or grid points. This step allows the assignment of relevant model attributes based on interpolated data.
Elements in the model file are assigned NKID numbers only if the respective station/grid point falls within the boundaries of the element or its nodes. Elements that do not meet this criteria are automatically assigned NKID = 0. This ensures that only the elements that correspond spatially to the input data points receive the specific ID, while the rest remain unassigned.
The inverse square weighting is the default interpolation method. This method operates under the principle that the closer the station/grid point is to anelement, the greater its influence on the assigned value. This inverse relationship ensures that closer points have a stronger influence on the interpolation, making the results more sensitive to local conditions. Users are required to adopt search radius based on the distance of the grid points,and the number of interpolation points to be considered. This ensures that the interpolation process reflects the spatial configuration and density of the input stations or grid points, providing accurate results. Adjusting these parameters properly can prevent issues like over-interpolation or under-interpolation in areas with sparse data
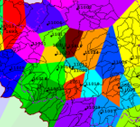
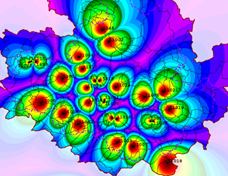
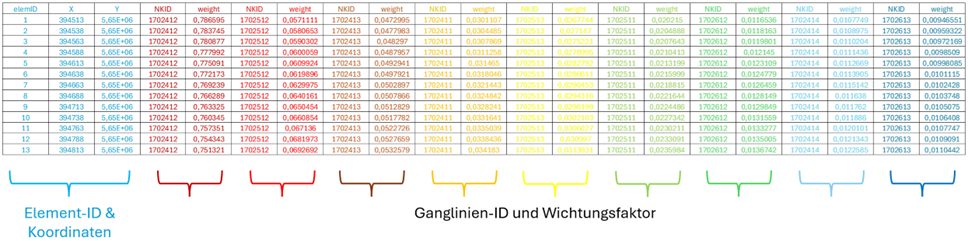
The output of this process is an input_id_weight.csv file which contains the NKID number and its weighting for each element (optionally with x-, y-coordinates of the centre point of each element if selected by the user). If the input_id_weight.csv file is available in the model directory, the weighting is automatically incorporated into the model calculation with the Sitra module. This ensures that the influence of each station or grid point on the model elements is properly considered during the analysis. The following illustration demonstrates the effect of interporaltion method on the weighting of station/grid parameters.
|
|
|
|
Parameters without weighting |
Parameters with inverse square weighting |
|
|
|
The resulting "input_id_weights.csv" (with output of the coordinates) has the following format:
The weighting factors from input_id*.csv apply to ALL calculation parameters present in the files (e.g. P, ET0, wind, temperature, etc.)!
Stand: 11.04.2025 | 