Bei der stochastischen Zuweisung von Daten wird zwischen korrelierten und unkorrelierten Daten unterschieden.
Unkorrelierte Generierung
Bei der unkorrelierten Generierung der Daten wird keine Ähnlichkeit der Daten in Abhängigkeit von deren Lage zueinander berücksichtigt.

Stochastisch generierte Daten ohne räumliche Korrelation
Eingabefenster: Unkorrelierte Generierung
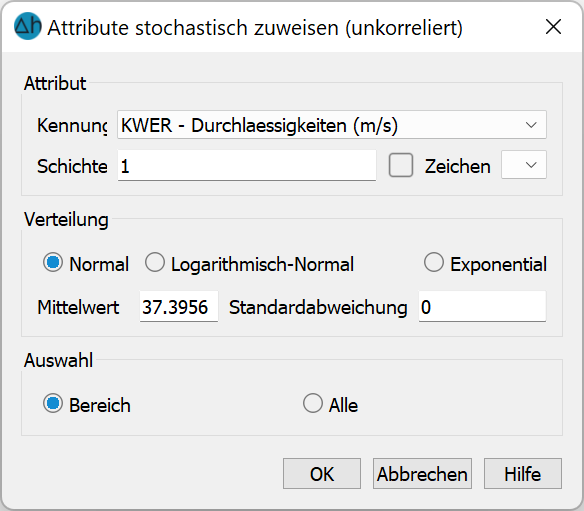
Zunächst erfolgt die Auswahl des Attributs, des Attributzeichens und der Schicht (bei 3D-Modellen).
Bei der Generierung unkorrelierter Daten kann zwischen der Normal-, Log-Normal- und der Exponential- Verteilung gewählt werden.
Es wird der Mittelwert (μ) der zu generierenden Werte im Gleitpunktformat eingegeben.
Es wird die Standardabweichung (σ) der zuzuweisenden Verteilung eingegeben. Die Eingabe einer Standardabweichung bei Wahl der Exponentialverteilung ist nicht notwendig!
Die generierten Werte können bereichsweise oder allen Knoten bzw. Elementen der Schicht zugewiesen werden.
Korrelierte Generierung
Korrelierte Daten werden von SPRING mit Hilfe des "turning bands" -Verfahren generiert (vgl. z.B. "A. Tompson, R. Ababou, L. Gelhar"; Implementation of the Three-Dimensional Turning Bands Random Field Generator; Water Resources Research; Vol. 25, No. 10, 1989). Der implementierte Algorithmus geht von einem exponentiellen Ansatz für das Variogramm aus, bei dem die Korrelationslängen in den drei Raumdimensionen verschieden sein können.
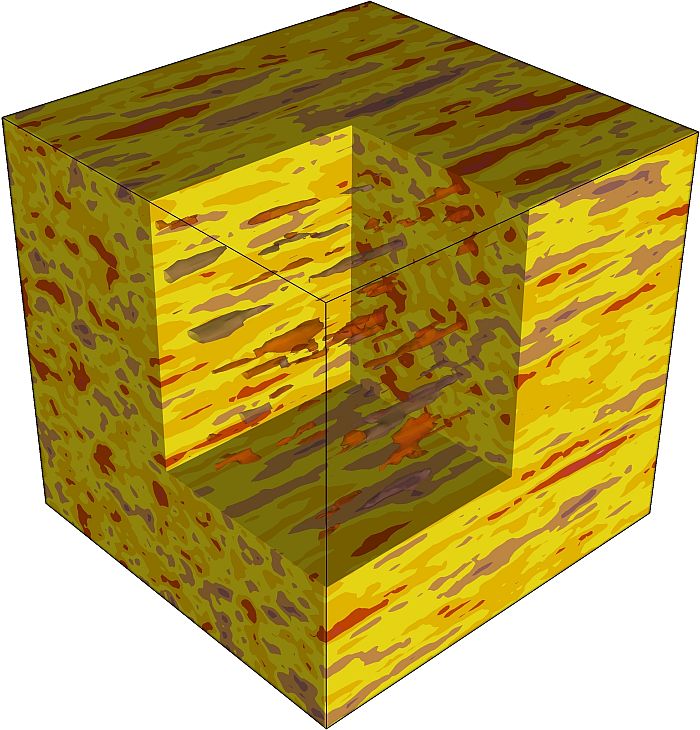
Stochastisch generierte Daten mit räumlicher Korrelation
Eingabefenster: Korrelierte Generierung
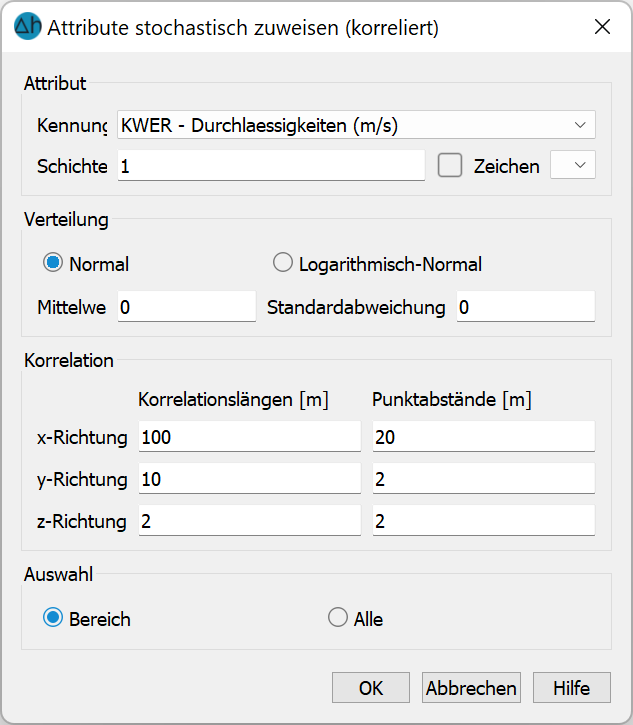
Zunächst erfolgt die Auswahl des Attributs, des Attributzeichens und der Schicht (bei 3D-Modellen).
Im Gegensatz zur unkorrelierten Generierung kann bei korrelierten Daten nur zwischen der Normal- und der Log-Normal-Verteilung gewählt werden.
Bei der Generierung korrelierter Daten mit dem Turning-Bands-Verfahren ist die Eingabe der Korrelationslängen (in m) notwendig. Für eine vernünftige Realisation muss die Netzdichte wesentlich kleiner sein als die eingegebene Korrelationslänge. Der Bereich, innerhalb dessen Werte generiert werden sollen, muss mehr als doppelt so groß sein wie die Korrelationslänge in der entsprechenden Richtung.
Der implementierte Algorithmus benötigt eine "verallgemeinerte" Information über die Netzdichte. Die hierzu einzugebenden Punktabstände sollten zwischen der kleinsten und den mittleren Seitenlängen in den entsprechenden Richtungen liegen. Die Güte der Realisation wächst, je kleiner die hier eingegebenen Zahlen sind.
Der Rechenaufwand für die Generierung korrelierter Daten wächst sehr schnell mit der Anzahl der zu genierenden Daten und kleinen Punktabständen.
Erst bei genügend großer Anzahl generierter Daten und (bei der korrelierten Generierung) der Beachtung der oben erläuterten Beziehungen zwischen Netzdichte, Punktabständen und Korrelationslängen entsteht bei der Zählung der generierten Werte ein für die Verteilung typisches Bild.
 Verteilungsfunktionen
Verteilungsfunktionen
Stand: 17.11.2023 | 