Definition of Data Identifiers
A complete model requires input data at the mesh nodes and elements. These data are known as mesh properties (permeability, thickness, geographic height, in- and outflow rates etc.). Each parameter has a data identifier (four letters) to manage the different kinds of data. They are described in Chapter: Data Structure of the Groundwater Model –Description of Data.
The data management in SPRING requires information on whether the data are related to nodes or elements and whether they have some special characteristic to be considered, e.g. data for polygonal lines or data which are limited to the topmost layer in a 3D model. With some exceptions, more information on the meanings is not necessary when creating the model. At this point, it does not matter whether the values of BERG are less than zero, or whether the geographic height at some nodes lies beneath the z-coordinate of the topmost layer. Hence, the data identifications are initialized directly with the help of the file xsusi.kenn. (This is different from the procedure in the model checking.)
The file is installed here:
Besides the general classification of the reference nodes or elements, it is the distinction between:

Simply used data: each node or element can receive only one value per layer for this type of data (eg: a node of a layer can have only one potential head (attribute POTE) and an element of a layer can have only one k-value (attribute KWER)). If a node or element of such a data type has been for any reason assigned twice, a specific query dialog appears. In it, the user can determine whether the first value (no overwriting) or the last value in the model file (ALL overwriting) should be stored.

Group data: each node or element can receive multiple values per layer for this type of data (eg, a node can be assigned to several mass balance areas (eg. BILA).
Polyline data (at node data): The data value is defined for a polygon of nodes, ie the order of node numbers plays a crucial role in the type of data (eg. Attributes LERA, MXKI, MXKE,…).
2D or 3D data: There are data types for which an allocation to deeper layers is not allowed. These have to be initialized as 2D data so that an allocation on layer numbers > 1 is not possible (eg: , MAEC, UNTE, UNDU, ...).
In the file xsusi.kenn are the identifiers initialized as follows:
At first, the line ".KENNUNGEN." is sought in the file. Thereafter, the following data is read per line until the end of file or finding a line beginning with ".ENDE.":
|
Column 1 - 4 |
KENN |
Four letter identifier of the data type |
|
Column 6 |
k, e, 1, 2 |
k = node related e = element related 1 = 1D fractures 2 = 2D fractures |
|
Column 7 |
empty, g, s |
empty = single used data g = group data s = polyline data (only in combination with k) |
|
Column 8 |
2, 3 |
2 = 2D data 3 = 3D data |
|
from Column 10 |
Any text as information for the identification |
|
Extract of the file xsusi.kenn as an example of the attribute description:
.IDENTIFIER.
ABRI k 3 Tear-off heights
AKON k 3 Initial concentrations
ASAT e 3 Initial saturation
BERG k 2 Terrain settings
BILE e 3 Bilance elements
BILK k 3 Bilance node
DISP e 3 Dispersitivity
EEEE e 3 General elementwise data
EICH k 3 Nominal potential head from calibration
FLAE e 2 Areal seepage (recharge rate)
FLUR k 2 Distance between ground level and water level
GELA k 2 Ground level
GLEI ks3 Equal potential head
GRUB k 3 Balance node for Flood Method
KKKK k 3 General nodewise data
KMAX e 3 Max. permeability (m/s)
KMIN e 3 Min. permeability (m/s)
KNOT k 3 Nodewise in-/outflow (+/-)
KONT ks3 Controll Lines
KONZ k 3 Inflow concentrations
KSPE k 3 Storage coefficient (nodewise)
KVRN e 2 Land use RVR
KWER e 3 Permeability (m/s)
KWEV e 3 Vertical permeability (m/s)
.END.
Unknown or user specified identifiers
The user can also specify any identifiers in the structure file. When opening the project with SPRING in this case, the following input window appears:
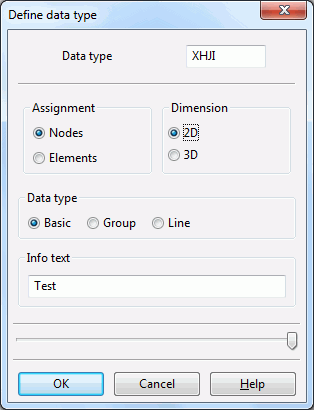
The user can then define whether it should be a node or element related data of the type "Basic", "Group" or "Line". If this new data type should be made permanent, it must be entered in the (user-specific) file xsusi.kenn.
Default parameters of the representation of the attributes
With the help of the file xsusi.kenn, you can modify the default parameters of the representation of the attributes. The default settings for displaying attributes are defined as:
individual used node data (eg. , EICH, POTE): 10 contour lines with equidistant partition
individual used element data (eg. FLAE, KWER): an area plot with 10 colour intervals (equidistant partition)
group data (eg. BILA): a plot of circles with 10 colour intervals (equidistant partition)
polyline data (eg. LERA, MXKI): a plot of polylines with 10 colours at maximum (equidistant partition)
Especially for the single used data that are usually only defined locally at single nodes (eg POTE or KNOT) the default settings are not usable.
In the file xsusi.kenn the default parameters of the representation of the attributes are initialized as follows:
After the definition of the data identifiers the line beginning with „.DARSTELLUNG.“ is sought. Thereafter, the following parameters are read per line until the end of file or finding a line beginning with ".ENDE.":
Line 1:
Column 1: * : stands for the initialization string of a new identifier
Columns 2 – 5: KENN: stands for the four letter identifier of the data type
Column 7: layer number
Line 2:
Column 1:
Thereafter follows the number of the colour palette (plot of areas or circles) or the colour number for the plot of contour lines.
For a plot of circles you can then define the height of the marker rmax <= 6.0 (for the maximum found value). Should all circles have the same height the chosen radius has to be rmax = 6.0.
Line 3:
These columns are without formatting. At first the parameter for the partition is defined:
0: equidistant partition
1: from/to/number
2: from/to/number (logarithmical)
3: from/to/distance
4: Single values
After the partition type 0, 1, 2 and 4 follows the number of intervals or the numbers of the single values.
In case of the partition type 1 to 4 follows:
Line 4:
Type 1 and 2: three values free formatted: from, to, number
Type 3: three values free formatted: from, to, distance
Type 4 with k or i: number of values for the plot of contour lines or for the interval limits of the circle plot (free formatted).
Type 4 with f: twice the number of values with the minimum and maximum interval limit (free formatted)
Extract of the file xsusi.kenn as an example of the representation description:
.DARSTELLUNG.
*AKON 1 /* Equal-value lines pen 5 */
i 5
0 10
*ASAT 1 /* Equal-value domains with palette 0 */
f 0
0 30
*BERG 1 /* Equal-value lines pen 5 */
i 5
0 10
*BILE 1 /* Equal-value domains with palette 0 */
f 0
0 10
*BILK 1 /* Circles with equal radius with palette 0 */
k 0 6.0
0 10
*DISP 1 /* Equal-value domains with palette 0 */
f 0
0 10
*EEEE 1 /* Equal-value domains with palette 0 */f 0
0 10.