The algorithm differentiates between correlated and uncorrelated data.
Uncorrelated generation
The uncorrelated generation does not take into account any similarity of data depending on their position relative to one another.

Stochastically generated data without spatial correlation
Input window: Uncorrelated generation
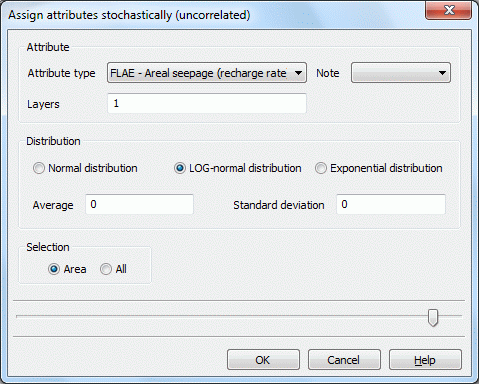
At first, the attribute, the attribute-note and the layer (in a 3D model) is defined.
For the generation of uncorrelated data the normal-, log-normal - and the exponential- distribution is available.
The textbox Average requires the input of the mean value (μ) of the values to be generated as a floating point number. The standard deviation (σ) of the used distribution is required. The input of a standard deviation for the exponential distribution is not necessary!
The generated values are assigned partially or to all nodes or elements of the layer.
Correlated generation
The correlated generation of data in SPRING is based on the turning bands method (see also "A. Tompson, R. Ababou, L. Gelhar"; Implementation of the Three-Dimensional Turning Bands Random Field Generator; Water Resources Research; Vol. 25, No. 10, 1989). The implemented algorithm works with an exponential function for the variogram where the correlation lengths can be different for the three spatial dimensions.
Stochastically generated data with spatial correlation
Input window: Correlated generation
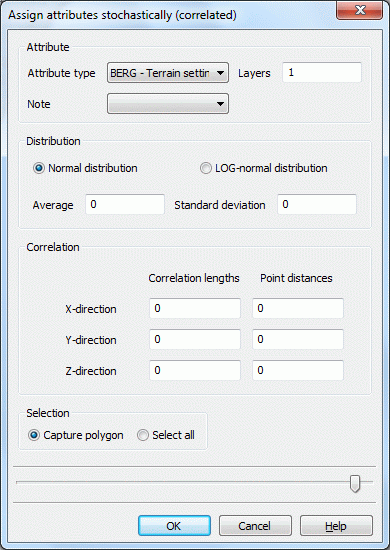
At first, the attribute, the attribute-note and the layer (in a 3D model) is defined. For the generation of correlated data only the normal and the log-normal but not the exponential distribution are available.
For generating correlated data using the turning bands method the input of correlation lengths (in m) is necessary. It only makes sense for the following two conditions are fulfilled: the mesh density, i. e. the element size has to be significant less than the defined correlation length. The region the values are generated inside has to be at minimum twice as large as the correlation length in the corresponding direction.
The implemented algorithm requires general information on the mesh density. The Point distance to be inserted in the corresponding textbox should lie between the smallest and the mean element sizes in the corresponding directions. The quality of the generated data will be better when these parameters are defined as finely as possible. Admittedly, finer values will increase the processing-time requirement.
The typical density function for the generated values will only result for a sufficient number of generated values. Additionally, for the case of a correlated generation, the relationships between mesh density, node ditch and correlation length mentioned above should be fulfilled.
 Distribution functions
Distribution functions