Es empfiehlt sich, zunächst einen Lauf mit 0 Iterationen durchzuführen. So kann ohne großen Aufwand die Zielfunktion kontrolliert werden. Die Ergebnisse werden in die Ausgabedatei (hier: out.inv) geschrieben, dabei werden die Anteile pro Parameter/Messwertgruppe einzeln aufgeführt.
Wichtig ist, die Anteile der Zielfunktion ausgeglichen zu gestalten. Nach dem ersten inversen Berechnungslauf (0 Iterationen) können die Anteile der Zielfunktion miteinander verglichen werden. Die am besten bekannten Größen (meist Potentiale) sollten dabei den größten Anteil an der Zielfunktion (ZF) haben.
Mögliche Fehlerquellen:

K-Werte sind zu stark gewichtet. Damit ist es dem Algorithmus nicht erlaubt, den K-Wert weit vom Schätzwert zu berechnen, und es ergeben sich fast keine Änderungen in der Verteilung der Durchlässigkeiten.
Mengen sind zu stark gewichtet. Somit verlieren die Messungen der Potentiale an Gewicht und der Algorithmus versucht (vergeblich!), die Mengen zur Übereinstimmung zu bringen. Meistens gilt die Regel: Stimmen die Potentiale und die K-Werte, sollten die Mengen sich auch einstellen.
Messreihen instationär: Im Piezometer x wird über ein Jahr jeden Tag gemessen, in Piezometer y hingegen nur 1x pro Monat. Wenn alle Einzelmessungen das gleiche 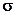 haben (also gleich stark gewichtet werden), wird in der Summe die Grundwassermessstelle x rund 30 Mal stärker gewichtet als die Grundwassermessstelle y (365 Messungen gegenüber 12 Messungen).
haben (also gleich stark gewichtet werden), wird in der Summe die Grundwassermessstelle x rund 30 Mal stärker gewichtet als die Grundwassermessstelle y (365 Messungen gegenüber 12 Messungen).
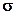 für Piezometer y kleiner wählen.
für Piezometer y kleiner wählen.
Sind die Anteile an der Zielfunktion ausgeglichen, wird die Anzahl der Iterationen auf 10 gesetzt und die inverse Modellierung erneut gestartet.
Ausgabedateien
out.inv
 Modelldaten/Berechnungsergebnisse importieren… direkt auf dem Attribut KWER abgelegt werden.
Modelldaten/Berechnungsergebnisse importieren… direkt auf dem Attribut KWER abgelegt werden.Invpar.csv:
Invpar_xy.csv:
resan_pote.csv, resan_lkno.csv, resan_knot.csv (nur stationär):
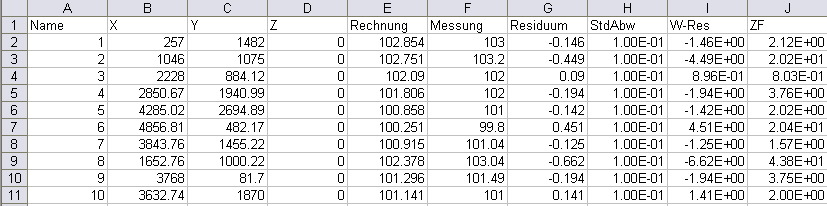
Beispiel der Datei resan_pote.csv
name.csv (nur instationär):
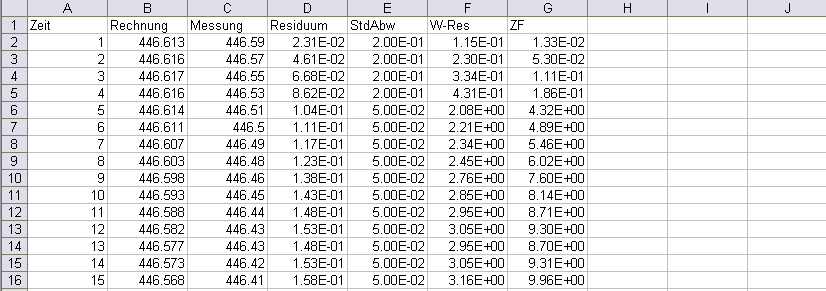
Beispiel einer instationären Ausgabedatei name.csv